🎨 AI Data Visualization Infographic🎯 infographic📅 2026-06-08
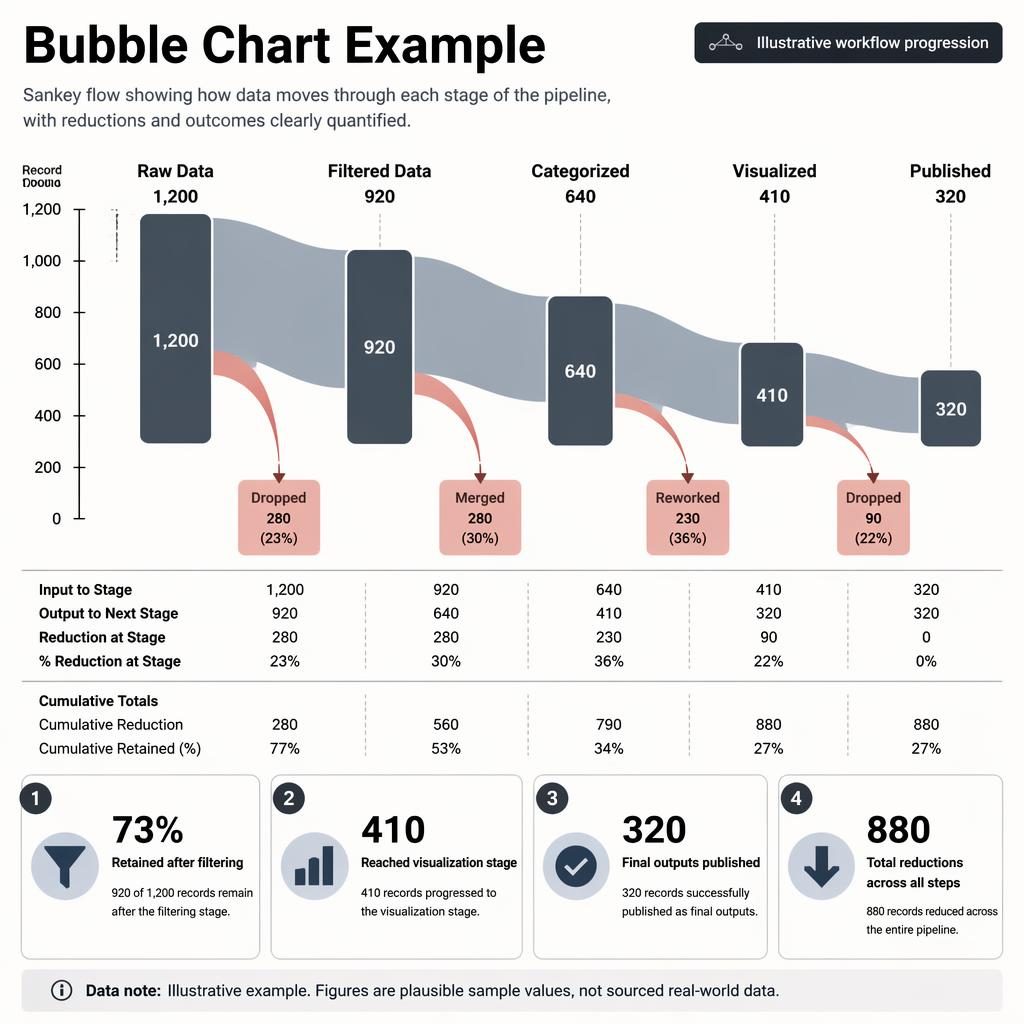
Grafana Multiple Data Sources Sankey Progress Infographic
Clean editorial infographic featuring a monochrome sankey flow for grafana multiple data sources, mapping pipeline progress from logs, metrics, traces, and events to rendered dashboard panels. FT/Bloomberg-style data journalism aesthetics, grayscale callouts, and precise loss annotations create a modern analytical brand visual.
Re-render this exact infographic with every label, heading and caption translated. We re-use all the original attributes (topic, style, palette, …) and only swap the language.
Currently in English.
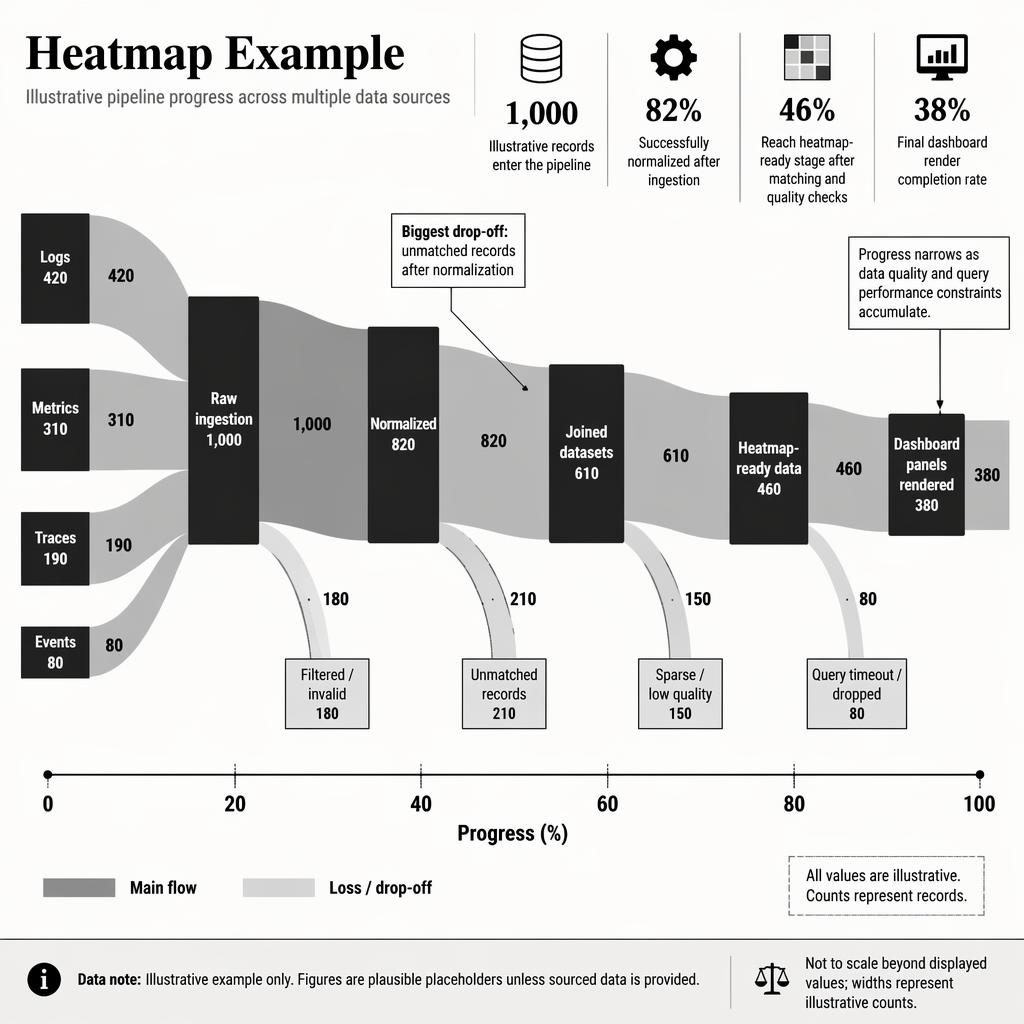
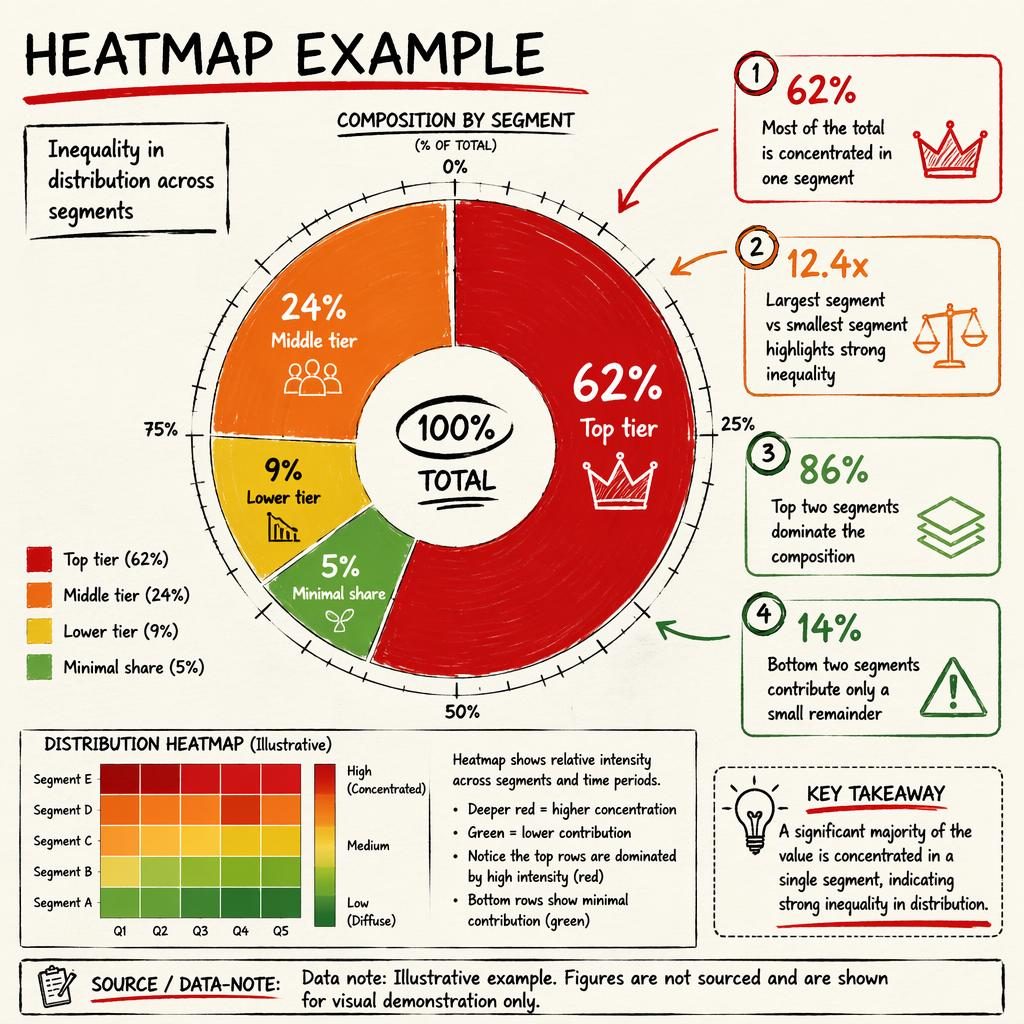
Data visualization infographic titled "Heatmap Example" using a SANKEY FLOW as the dominant visual element to show progress through a pipeline. Create a clean editorial data journalism illustration, FT / Bloomberg-grade chart aesthetics, vector-clean infographic layout. Monochrome ink palette only: deep black, charcoal, slate gray, light gray, off-white background, subtle contrast steps, crisp fine rules, restrained newsroom mood, analytical and modern.
Main visual: a large left-to-right sankey pipeline occupying most of the canvas, with sharp labels, clear node titles, precise flow widths, and an aligned progress scale with tick marks in English along the bottom from 0 to 100 labeled "Progress (%)" with ticks at 0, 20, 40, 60, 80, 100. Add a small top subtitle in English: "Illustrative pipeline progress across multiple data sources". Use realistic plausible illustrative values and clearly mark them as illustrative.
Sankey structure and exact on-image labels in English:
- Left source nodes: "Logs" = 420, "Metrics" = 310, "Traces" = 190, "Events" = 80
- Merge stage node: "Raw ingestion" = 1,000
- Next node: "Normalized" = 820
- Split losses from Raw ingestion to side node: "Filtered / invalid" = 180
- Next node: "Joined datasets" = 610
- Split losses from Normalized to side node: "Unmatched records" = 210
- Next node: "Heatmap-ready data" = 460
- Split losses from Joined datasets to side node: "Sparse / low quality" = 150
- Final node: "Dashboard panels rendered" = 380
- Split losses from Heatmap-ready data to side node: "Query timeout / dropped" = 80
Ensure flow conservation is visually correct and numerically consistent. Make the sankey links thick, elegant, and clearly readable in grayscale. Place values directly on or beside major links as digits. Add concise legends in English only: "Main flow" and "Loss / drop-off".
Add 4 key insight callouts around the chart, each with a small monochrome icon, a headline number, and a short interpretation in English:
1. "1,000" — "Illustrative records enter the pipeline" — icon: database cylinder
2. "82%" — "Successfully normalized after ingestion" — icon: settings/gear
3. "46%" — "Reach heatmap-ready stage after matching and quality checks" — icon: grid/heatmap
4. "38%" — "Final dashboard render completion rate" — icon: monitor/chart screen
Add a small annotation near the largest loss point: "Biggest drop-off: unmatched records after normalization" with a pointer line to the 210 loss branch. Add another annotation near the final stage: "Progress narrows as data quality and query performance constraints accumulate".
Typography and layout: strong headline, compact subhead, disciplined spacing, sharp axis labels and tick marks, thin divider lines, small legend, note boxes with subtle gray fills, balanced margins, print-ready newsroom infographic composition. No misleading axis truncation or scale manipulation.
Add a bottom strip in English for source/data note exactly as: "Data note: Illustrative example only. Figures are plausible placeholders unless sourced data is provided." Include a tiny note: "Not to scale beyond displayed values; widths represent illustrative counts."
All text MUST be written in English (array). Every heading, label, caption, legend and metric name in the image must be in English — not English. Spell each English word correctly using English characters and diacritics. Numbers stay as digits, no fake authoritative sources cited, no watermarks Numbers labeled "illustrative" unless the user supplied specific sourced data. No fake authoritative sources cited (do not invent "Source: Reuters 2025" — use "Illustrative example" instead). No misleading axis truncation or scale manipulation.
Report inappropriate content
Tell us why this image is inappropriate. A description is required — generic submissions are dismissed.
Confirmed reports are resolved within 24 hours.